REVENUE DRIVEN FOR OUR CLIENTS
$500 million and counting CLIENT LOGIN
CLIENT LOGIN
- Who We Help
- Industries
- The presence of HTTP and HTTPS versions of the same URL
- Multiple pages ranking for the exact long-tail keywords
- URLs without a trailing slash “/”, capitalizations, and query parameters.

Having duplicate content on your business website is a nightmare for any business owner. Such occurrences (even at the slightest) hamper a business’s reputation and cause the website’s ranking on SERP to drop significantly. However, what is duplicate content, and why is there so much fuss about it? Let’s find out.
What is Duplicate Content?
Duplicate content refers to having the same content on your website as an existing one (the original content source). This content type can be exact or similar to the original content. Having massive amounts of duplicate content on your website reduces its credibility and authenticity in the eyes of search engines. As a result, your website is less likely to be seen by your target audience, eventually leading to a drop in website traffic and conversion rates. The occurrence of duplicate content is common in e-commerce websites. This primarily happens due to the presence of duplicate content on similar product pages. In such cases, opting for reputed e-commerce SEO services can be immensely beneficial if your website has an extensive range of products.
For instance,
Original website content: Our tea range is carefully cultivated, ensuring every leaf is handpicked and processed using traditional techniques for the best taste.
Duplicate website content: Our tea range is carefully cultivated, ensuring every leaf is handpicked and processed using traditional techniques for the best taste.
Even if the content has been rewritten, it is still considered duplicate.
For instance,
Original website content: Our tea range is carefully cultivated, ensuring every leaf is handpicked and processed using traditional techniques for the best taste.
Duplicate website content: Our range of tea is carefully cultivated, and every leaf is handpicked and processed using traditional techniques to give it the best taste.
The original and duplicate content pieces read differently but convey the same thing, with words jumbled to deceive the reader and the search engine into believing they are different sentences.
The Impact of Duplicate Content on SEO

Search engines always seek information that helps users find relevant and accurate information. When these search engines come across duplicate content (that too if the original website is a reputed source with high domain authority), they are less likely to push it to rank higher on SERP.
Due to this, no matter how many pages your website has, if the content is duplicate, Google (and other search engines) won’t show your website to its users. The design of most search engines prioritizes indexing and displaying websites with unique information. Duplicate content on the website defeats this agenda.
On a deeper level, duplicate content harms the website on various levels, including:
Causes Indexing Problems
Duplicate content across different page URLs can confuse search engines when determining which version to prioritize. As a result, all the pages with duplicate content will rank low. This action often leads to a wasted crawl budget and diluted backlinks, making your website lose its credibility in the eyes of search engines.
Confuses Search Engine
Imagine listening to a similar-sounding song at the same time from different directions. Determining which song is being played precisely (even if it’s your favorite) gets confusing. The same is the case with search engines. When they come across the same or similar content, it gets confusing for them to determine which page will offer the best value to the readers. As the crawler finds it challenging to conclude, it does not prioritize pages with duplicate content.
Reduces Organic Traffic
As your website ranks low on search engines, the traffic flow significantly reduces. The obvious signs will be a lower traffic influx to your website and significantly reduced clicks for inquiries. With the drop in page views and traffic, your website can struggle to grab the attention of your target audience.
Reduces Link Equity
Acquiring high-quality backlinks is a crucial part of any SEO strategy. A website with duplicate content may end up with backlinks spread across different versions of the same content instead of directing to a single page. This uneven distribution of backlinks dilutes link equity, eventually reducing the page’s ability to rank.
Impacts User Experience
Duplicate content across multiple pages makes it challenging for your target audience to find the information they seek. As a result, they are likely to exit the website sooner, feeling frustrated and vowing never to return. In many e-commerce marketing services, product pages are carefully tackled to avoid repeating content. It’s misleading and often leaves the website visitor unsure about making a purchase. With this, the conversion rate continues to soar, and the customer feels more confident in making a purchase.
How to Identify Duplicate Content

Identifying duplicate content is crucial; if not taken care of on time, your website will plummet in the SERP. Here is how to identify instances of duplicate content:
Manual Inspection
This method involves using Google Search to find duplicate content instances. To get started with this step, copy and paste 32 words from the suspected duplicate content on the search engine. The results will highlight similar results to the initial search query. These results often match up and indicate content being duplicated. This method is simple and effective.
Google Search Console
Using Google Search Console is the easiest way to find duplicate content. Check for the Search Results tab under the Performance section. There you will discover URLs with duplicate content instances. The common signs you must look for are
Their presence strongly indicates the presence of duplicate content on your website.
Plagiarism Detection Tools
Many e-commerce content marketing agencies rely on using plagiarism detection tools to avoid having product descriptions that are exact matches of what’s already available on other websites. These tools are designed to detect duplicate content, even if scattered across a website. All you need to do is run the suspected content on these tools. The tool will quickly scan the Internet and show parts of the copied content and their sources. These tools are efficient and allow multiple pages to be checked.
SEO Tools
SEO tools also offer the feature of checking duplicate content on a website. They do this by crawling through the website and finding webpages with duplicate content highlighted under the content tab.
Technical Checks
Checking the presence of the same or strikingly similar metadata on multiple pages can indicate the potential issue of duplicate content. It’s essential to check the highlighted pages, including the URLs and the overall page’s content.
Google Search
Google is the largest search engine ever to exist and is often preferred by most people. To check if the content on your website is duplicate, consider pasting a part of the suspect content into Google. The search engine will quickly scan through multiple pages and show pages where the duplicate content is potentially from.
Common Causes of Duplicate Content
Recognizing the common causes of duplicate content is crucial. It helps remove processes that can lead to duplication. Know that aside from producing similar or the same content,
URL Variations
URL variations refer to different versions of HTTP/HTTPS, with/without www in the website’s architecture. Other reasons can include trailing slashes, which are often perceived as the same content appearing on multiple URLs.
Session IDs
Session IDs in URL viewing are common. In this process, every internal link on the website has a session ID added to its URL, as the ID is unique to the page-viewing experience. If the session IDs are misinterpreted, duplicate content can occur on multiple pages across the website.
Faceted Navigation
Faceted navigation occurs because every unique combination of filter selections generates a new URL. It happens because the content being displayed remains identical or similar. The search engine struggles to recognize which page version should be indexed, leading to diluted ranking signals and significantly reducing the site’s authority.
Pagination URLs
Pagination URLs are designed to make content on a website more organized. This process is done in manageable chunks, eventually creating duplicate content occurrences for search engines. Such action is often a result of each page in the pagination series being present in the same topic, even if they contain different information. This virtue confuses search engines, often resulting in duplicate pages (and, as a result, duplicate content).
HTTP vs. HTTPS and www vs. non-www Pages
The HTTP vs. HTTPS and www vs. non-www pages make the same content accessible across different pages on the website.
Scraped or Copied Content
Copied content is the most apparent reason for duplicate content on the website. During the content curation and writing, the original content (for inspiration) is rewritten or blatantly copied to fulfill the content requirements. This error leads to the presence of duplicate content across multiple URLs.
How to Fix Duplicate Content Issues
Fixing duplicate content concerns is relatively easy. If you have detected the presence of duplicate content on your website, here are some practical ways to tackle the problem with strategic planning:
Set a Preferred Domain
Setting a preferred domain is crucial to avoid duplication of website page URLs. A preferred domain is the specific version of your website that you want search engines to crawl whenever they access your site consistently. This arrangement refers to www.website.com rather than just website.com. With this, only one domain is present on the sitemap: the one you have selected. This arrangement prevents other webpages from getting crawled and reduces the chances of URLs having the same content.
Implement Proper URL Structure
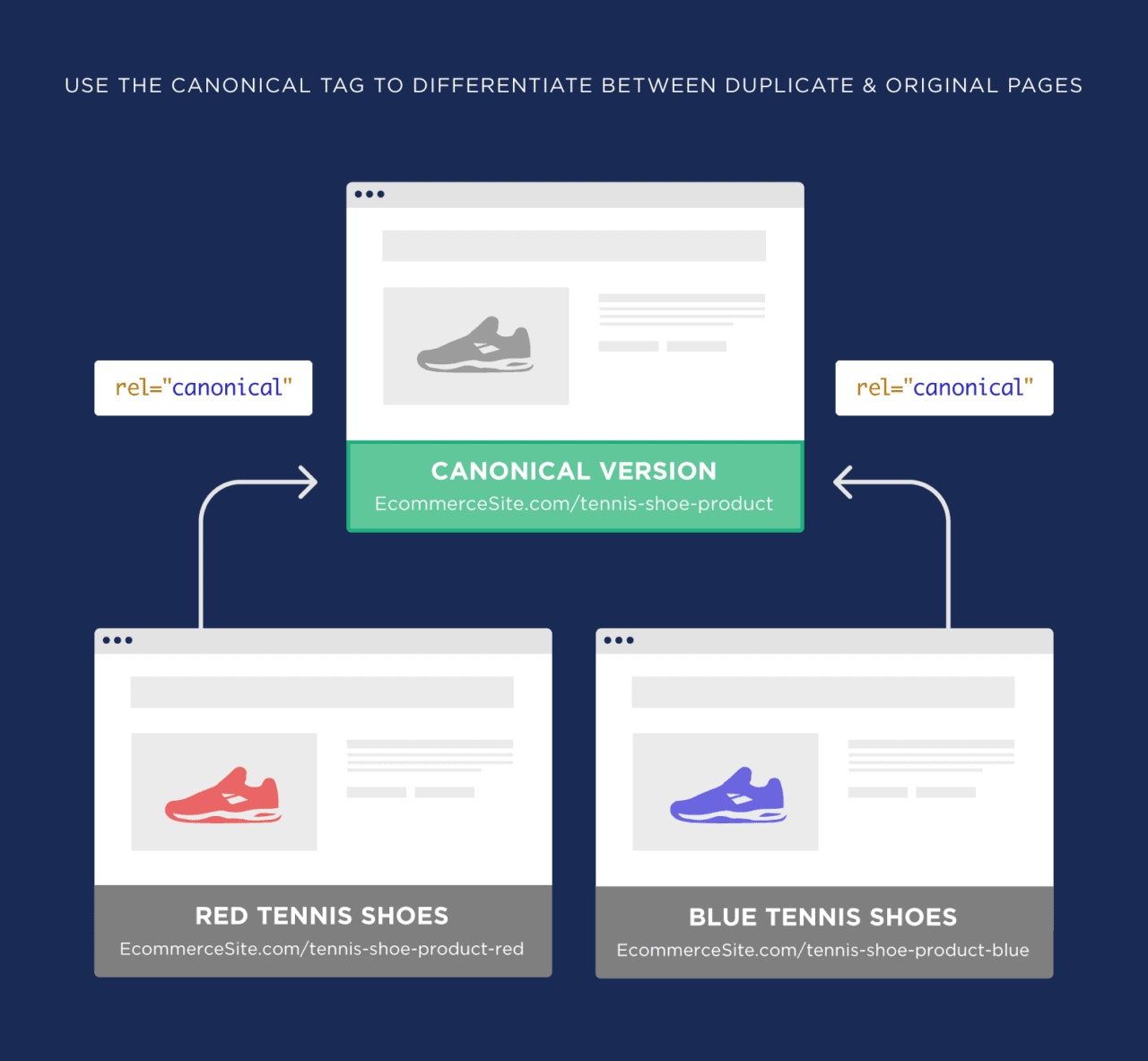
An adequately laid-out website URL structure is immensely beneficial in avoiding duplicate content. It is achieved by implementing clear and consistent efforts to make it easier for search engines to identify the primary canonical version of a page. A well-defined structure prevents search engines from thinking that multiple URLs with the same content are associated. Adding redirects and appropriate canonical tags is another key strategy often used to prevent search engines from considering various pages as the same.
Canonical Tags
A canonical tag is a snippet of HTML. It’s used to indicate the main canonical URL. By specifying canonical tags correctly, websites can ensure that only the URL with the main content gets indexed. With this move, only the page with quality content shows up.
Use 301 Redirects
If you are not planning on deleting the duplicate pages on your website, opting for a 301 redirect is a great way to resolve the issue. This method works by redirecting users to the original page from the duplicate pages. Once the search engine lands on the page with duplicate content, it will move to the source without indexing the duplicate page.
Robots.txt
The robots.txt file tells search engines which pages they can crawl and which they shouldn’t. This is a common technique for managing crawl traffic. It prevents the website from being overloaded with search engine requests and maximizes your crawl budget.
Use Noindex Tags
Noindex tags tell search engines the page they don’t need to crawl or index when they are on your website. This strategy is beneficial when trying to manage syndicated content (which is content posted on other websites with your permission). Due to this, these tags must be added to syndicated content.
The most common format of noindex tags often looks like
<meta name=”robots” content=”noindex” />
Rewrite Content
If nothing works, investing time, effort, and resources into creating new content is best. Such efforts will give your website a facelift while allowing you to curate content that aligns with your business objectives. To ensure the latest content aligns with your goals, focus on building a content marketing strategy that considers your growth needs while outlining the guidelines that need to be followed to avoid creating duplicate content again.
Ensure Proper Attribution in Content Syndication
Implementing proper attribution during content syndication involves crediting the content’s source. This is especially important when your content is reposted. This strategy includes adding backlinks, canonical tags, and clearly defining the original publisher of the content.
Consolidate Duplicate Pages
Combine all the pages with duplicate content into one. If you do not want to eliminate duplicate webpages entirely, this is the best way to preserve your pages.
Maintain Consistent Internal Linking
Maintaining consistency in your internal linking strategy is crucial to prevent crawlers from getting confused about which page to index and rank. It also prevents link dilution.
Conclusion
Duplicate content is a serious concern for any website, regardless of size. Such content reduces your website’s credibility and authenticity while negatively affecting SERP ranking. To avoid this, it’s essential to recognize these pages and take a strategic approach to preventing damage to your website. Use advanced tools to identify duplicate content pages and actively invest in your content management strategy to create valuable and unique content pieces. If you are unsure how to tackle occurrences of duplicate content, our experts at Wytlabs can help you get started.
We are a Value-driven Marketing Agency Working Exclusively for SaaS and E-commerce Businesses.
REVENUE DRIVEN FOR OUR CLIENTS
$500 million and countingServices
Business
About Us
Resources
© 2025 WYTLABS (A Brand of Digimagnet INC.) All Right Reserved.
Schedule My 30 Minutes Consultation Call

Get a Proposal
- Industries


 99 South Almaden Boulevard, San Jose, California, 95113
99 South Almaden Boulevard, San Jose, California, 95113